10 minutes to cuxfilter¶
This is a short introduction to the cuxfilter.py library, mostly going over the basic usage and features provided as a quick summary.
What is cuxfilter.py?¶
cuxfilter is inspired from the Crossfilter library, which is a fast, browser-based filtering mechanism across multiple dimensions and offers features do groupby operations on top of the dimensions. One of the major limitations of using Crossfilter is that it keeps data in-memory on a client-side browser, making it inefficient for processing large datasets.
cuxfilter solves the issues by leveraging the power of the rapids.ai stack, mainly cudf. The data is maintained in a gpu as a GPU DataFrame and operations like groupby aggregations, sorting and querying are done on the gpu itself, only returning the result as the output to the charts.
cuxfilter acts as a connector library, which provides the connections between different visualization libraries and a GPU dataframe without much hassle. This also allows the user to use charts from different libraries in a single dashboard, while also providing the interaction.
cuxfilter uses data-tiles on the front-end, which are precomputed aggregations, for all possible interactions for a single chart, for updating all remaining charts in a dashboard. data-tiles are just smartly computed groupbys, and generally take around 250ms per chart for a 100M row dataset(do the rest of the math!!!!, ps: its fast!). Once it’s downloaded, interactions are seamless, and well, realtime.
The modules¶
cuxfilter has following usable modules
cuxfilter.DataFrame
cuxfilter.DashBoard
cuxfilter.charts
cuxfilter.layouts
Usage¶
1. Import the required modules¶
[6]:
from cuxfilter import DataFrame, themes, layouts
from cuxfilter.charts import bokeh, datashader, panel_widgets
2. Read some data¶
cuxfilter can read arrow files off disk, or an inmemory cudf dataframe
[8]:
#create cuxfilter DataFrame
cux_df = DataFrame.from_arrow('../../data/auto_accident_loc_data.arrow')
cux_df.data['ST_CASE'] = cux_df.data['ST_CASE'].astype('float64')
cux_df.data.head()
[8]:
| STATE | ST_CASE | VEH_NO | PER_NO | COUNTY | CITY | DAY | MONTH | YEAR | DAY_WEEK | ... | ROUTE | RELJCT2 | AGE | LAG_HRS | ALC_RES | UNITS_SOLD | LATITUDE | LONGITUD | dropoff_x | dropoff_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 10001.0 | 1 | 1 | 831 | 968 | 19 | 2 | 2017 | 1 | ... | 1 | 1 | 42 | 0 | 0.96 | 186161.0 | 33.335661 | -87.007094 | -9.685585e+06 | 3.939943e+06 |
| 1 | 1 | 10002.0 | 1 | 1 | 1009 | 5923 | 14 | 2 | 2017 | 3 | ... | 1 | 1 | 43 | 0 | 0.00 | 150219.0 | 34.661528 | -86.786853 | -9.661068e+06 | 4.117979e+06 |
| 2 | 1 | 10003.0 | 1 | 1 | 1120 | 8314 | 31 | 1 | 2017 | 3 | ... | 1 | 1 | 63 | 999 | 0.00 | 0.0 | 32.366519 | -86.145281 | -9.589649e+06 | 3.811519e+06 |
| 3 | 1 | 10003.0 | 2 | 1 | 1120 | 8314 | 31 | 1 | 2017 | 3 | ... | 1 | 1 | 47 | 0 | 0.00 | 207479.0 | 32.366519 | -86.145281 | -9.589649e+06 | 3.811519e+06 |
| 4 | 1 | 10003.0 | 3 | 1 | 1120 | 8314 | 31 | 1 | 2017 | 3 | ... | 1 | 1 | 64 | 999 | 0.96 | 0.0 | 32.366519 | -86.145281 | -9.589649e+06 | 3.811519e+06 |
5 rows × 63 columns
3. Create some charts¶
see charts section to see available chart options
[9]:
from cuxfilter.assets.custom_tiles import get_provider, Vendors
[10]:
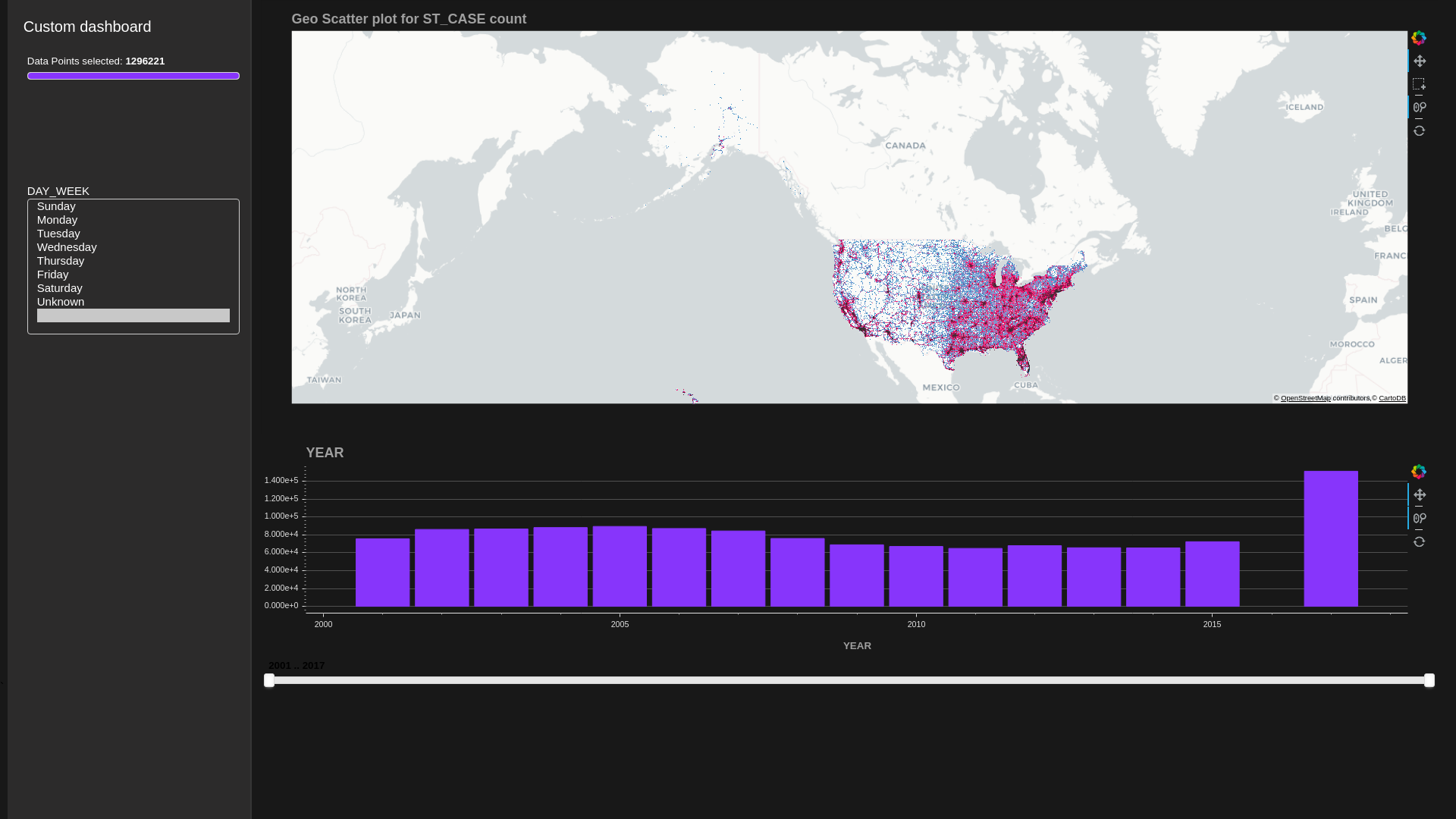
demo_red_blue_palette = [ (49,130,189), (107,174,214), (123, 142, 216), (226,103,152), (255,0,104) , (50,50,50) ]
chart1 = datashader.scatter_geo(x='dropoff_x', y='dropoff_y', aggregate_col='ST_CASE',
color_palette=demo_red_blue_palette)
chart2 = bokeh.bar('YEAR')
#creating a label map for days of week strings
label_map = {
1: 'Sunday',
2: 'Monday',
3: 'Tuesday',
4: 'Wednesday',
5: 'Thursday',
6: 'Friday',
7: 'Saturday',
9: 'Unknown'
}
chart3 = panel_widgets.multi_select('DAY_WEEK', label_map=label_map)
charts_list = [chart1, chart2, chart3]
4. Create a dashboard object¶
[11]:
d = cux_df.dashboard(charts_list, title='Custom dashboard', layout=layouts.feature_and_base, theme=themes.dark, data_size_widget=True)
5. View the dashboard¶
[12]:
#preview
await d.preview()
#for using the interactive web-app version, use d.app() for in notebook, and d.show() for using it in a separate window as a web-app
6. Run the dashboard¶
[13]:
"""
1. d.show('current_notebook_url:current_notebook_port') remote dashboard
2. d.app('current_notebook_url:current_notebook_port') inline in notebook (layout is ignored, and charts are displayed one below another)
Incase you need to stop the server:
- d.stop()
"""
d.show('notebook_url')
Dashboard running at http://notebook_url/proxy/60491/
6. After you do some interactions, you can take a snapshot of the current state and save it as a dataframe!¶
[14]:
current_state_df = d.export()
no querying done, returning original dataframe
[ ]: